
Nodepool virtual machines (worker nodes) are slow in provisioning from VMware TCA post TKG upgrade
Description of the issue:
After a successful TKG upgrade, when deploying the node pools via TCA (in bulk), the number of requests to the vCenter to initiate a cloning operation is very few. Only 2-3 requests are sent for cloning operations and TCA waits for the VMs to get deployed and starts the next one.
This resulted in timeouts, where we were deploying more than 80 node pools in the TKG cluster.
Cause:
- The root cause was due to errors in the reconciliation of machines. CAPV (the client in this case) was out of local ports and this led to errors when trying to establish a connection to vCenter. This ultimately delayed the cloning of the VMs.
- Some of the VSphereVMs can end at the back of the processing queue because of some transient errors (e.g. too many client-side connections).
Resolution:
- To mitigate the slow worker creation issue, we added the --enable-keep-alive flag on the capv-controller-manager deployment to re-use sessions as much as possible.
- We also changed the resync period from 10min, the default, to 5min by adding the --sync-period=5m0s flag.
- The resync period is the interval between each full reconciliation. This has no impact on resource usage, as only the frequency changes.
- This did cut down the slowness significantly.
- You can do the changes with the below command.
kubectl edit deployment -n capv-system capv-controller-manager
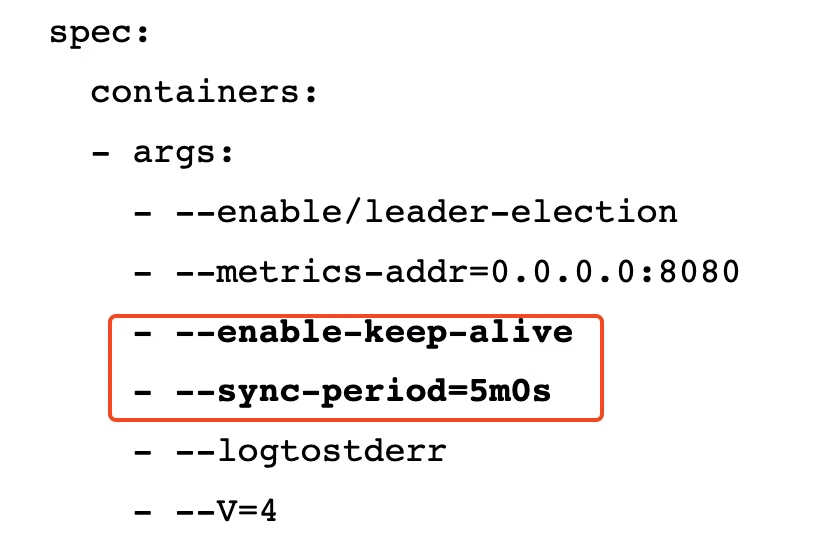
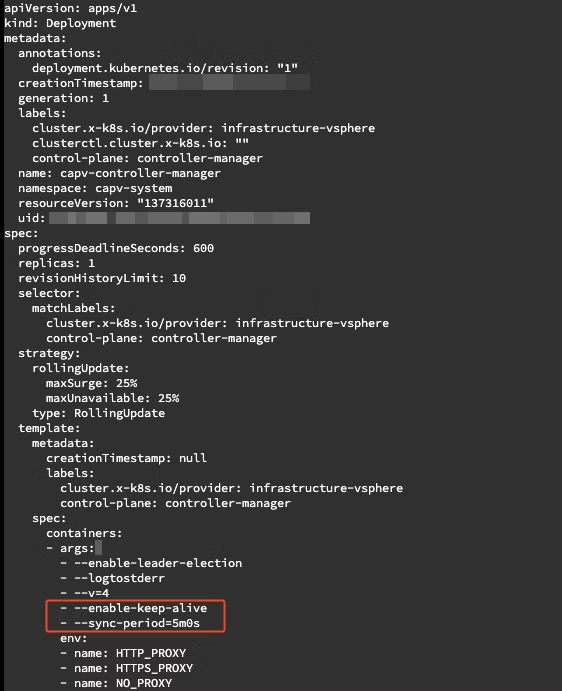
- Save and exit, which should cause the CAPV manager pod to be redeployed.
- This should ensure a more frequent overall sync by CAPV.
- This change is not persistent and will be overridden during the next management cluster upgrade.